





Voiceprint is a kind of non-contact biological feature, which has identity uniqueness like human face, iris, fingerprint, finger vein, palmprint and other human biological features, that is to say a sentence can uniquely determine an identity. Compared with other authentication technologies, voiceprint recognition is more convenient and safer.
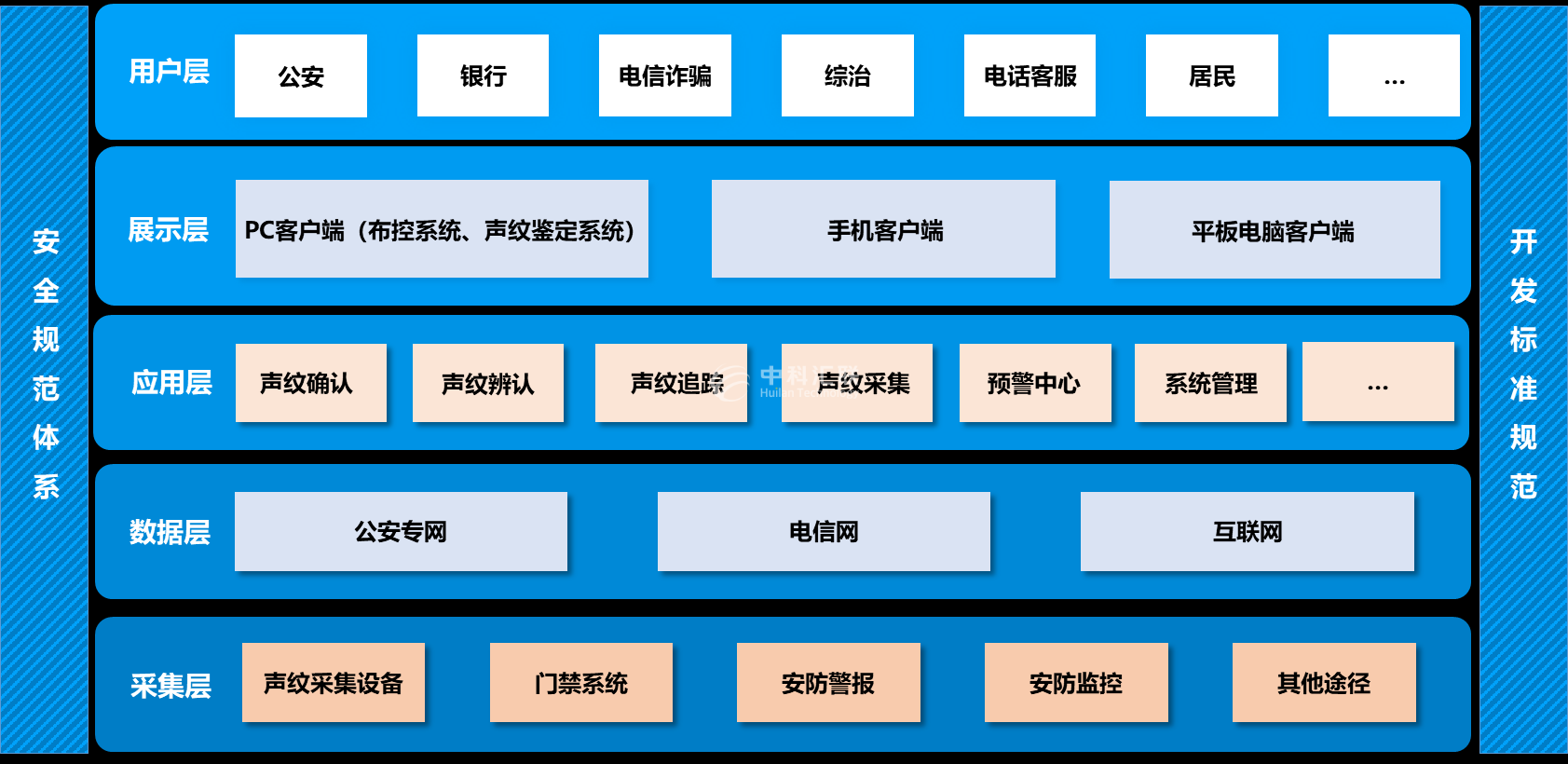
Beijing zhongkehuilian Technology Co., Ltd. (hereinafter referred to as "Huilan Technology") cooperates with the speech and language center of Tsinghua University to research and develop the core technology of voiceprint recognition, and forms the leading voiceprint recognition engine in China, so as to realize the voiceprint recognition service of "speech recognition". Provide contactless, perceptual and privacy free intelligent identification services for credit risk control anti fraud, identity authentication of call service center, mobile financial identity authentication and security monitoring.
The speech and language technology center of the intelligent voiceprint recognition technology team of Huilan Technology was founded in February 2007. Its team members are from the relevant research group of the school of information science and technology of Tsinghua University. The speech and language technology center includes three laboratories, namely the speech recognition Laboratory (ASR Lab, vprlab and nllab also employ well-known international and domestic experts to form Advisory Committee members to guide their construction and research and development of technologies and applications with independent intellectual property rights, and promote applied basic research and technological innovation.
All of the following standards, Tsinghua speech language experiment center, Huilan Technology, are drafting units and participate in the drafting work.
Technical requirements and test methods for application algorithm of security voiceprint confirmation, Ministry of public security GA / T 1179-2014
Terminology of security biometric identification TC100 / sc22010, Ministry of public security
Technical requirements for voiceprint recognition application system, Ministry of public security TC100 / sc22012
Technical specification for automatic voiceprint recognition (speaker recognition), Ministry of industry and information technology, 2008
Technical code for security application of mobile finance based on voiceprint recognition (JR / t0164-2018)
Financial sector - Working Group on biometric identification standards of CMB TC28 / sc372009
At present, China Construction Bank, China Minsheng Bank, Shanghai Pudong Development Bank, China Everbright Bank, China Guangfa bank and other banks have launched voiceprint products to provide a comprehensive guarantee for financial security. In foreign countries, Barclays Bank of England, Citibank of America, National Bank of Australia, MasterCard institutions have begun to introduce voiceprint technology.
Speech quality detection is the first pass of voiceprint recognition system. There are three kinds of speech endpoint detection methods provided by the intelligent voiceprint recognition solution, which are energy-based voice endpoint detection, depth speaker feature-based voice endpoint detection and depth speech feature-based voice endpoint detection. In different application scenarios, through the reasonable application of three endpoint detection methods, the detection of human voice and non-human voice, the separation of effective voice and invalid voice are realized efficiently and accurately.
Considering the common problems of speech quality in practical application, based on the above speech endpoint detection algorithm, we propose volume detection based on the energy size of invalid speech segment, noise detection based on SNR, pseudo intercept detection based on high frequency component statistics, etc. to evaluate the speech quality of input audio from multiple angles.
In order to improve the noise robustness of the voiceprint recognition system, our company has taken corresponding measures in the feature domain and model domain for different types of noise.
In the feature domain, for stationary additive noise, a power spectrum subtraction method is proposed to achieve noise suppression; for complex noise (curly, slowly varying, impulse noise), we propose a noise compensation model based on noise reduction auto encoder to map noisy speech features to clean speech features to achieve noise elimination.
In the model domain, we use the training mechanism of data enhancement to add noise data into the training of voiceprint model in the form of random Gaussian, which makes the trained model more robust to noise data.
In order to improve the robustness of phrase sound, a model training mechanism based on short frame level is proposed, which enables the model to complete the voiceprint recognition in a very short speech time (about 0.3 seconds). On this basis, we introduce more high-order statistical information and regularization criteria into the model training, which further improves the recognition accuracy of the model under the condition of short speech (2-3 seconds).
In addition to the above-mentioned solutions at the algorithm level, the smart voiceprint recognition solution of Huilan Technology also combines specific business scenarios to design dialogue content related to users, such as raising related issues or requiring reading protocol content. In this way, enough effective voice can be collected. Secondly, the user's identity can be further judged and the security can be further improved through the conversation content, such as the answers to related questions.
The model miniaturization method is adopted in the intelligent voiceprint recognition solution of cchi to solve the problems in practical application.
The compression method based on matrix or tensor decomposition is used to reconstruct the original matrix through the accumulation of several low rank matrices or tensors, so as to achieve the purpose of network storage compression.
The fixed-point training method is used to realize the quantification of network parameters. In addition, local sensitive hash or Hamming distance measurement can also be used to map the high-precision voiceprint model to an approximate binary space to complete the binarization of the voiceprint model, and the comparison of the two voiceprint models can be realized quickly through Hamming distance.
Network pruning based on neuron or connection edge is used to compress the network topology and sparse the network.
The intelligent voiceprint recognition solution of Huilan Technology adopts the rapid adaptation method of voiceprint model to solve the problem of being affected by recording equipment and business content in specific application scenarios.
The intelligent voiceprint recognition solution adopted different detection strategies from the perspective of feature domain and model domain, and solved the problems of voice imitation, voice synthesis, voice conversion and recording playback.
The voiceprint recognition solution of Huilan Technology can be seamlessly connected with the criminal specialized platform in use by the National Public Security Bureau, and the collected data can be distributed through the platform. It can be seamlessly connected with the standardized personnel information collection system in use in the National Public Security Bureau, and realize the unified management and application of the collected data through the standardized personnel information collection system for data collection and storage.
Voiceprint Library of Changping branch and Fangshan Branch of Beijing Municipal Public Security Bureau


Beijing Huilan Technology Co., 京ICP备05046823 Copyright © 2020 HuiLan.com All rights reserved.





 Monday to Friday 9:00-18:00
Monday to Friday 9:00-18:00 Customer Service Email
Customer Service Email Online Consulting
Online Consulting